This is a part of series Building a project, where I try to make something using OpenStack.
-
Learning about OpenStack
With a suggestion that I should work on a project to improve my skill set, I decided to join my partner in creating one together. I have recently decided to dive into the world of cloud computing, but I lacked knowledge in just about everything. I was still eager to present myself with challenges, however, so I jumped right in.
What should the project do?
After hours of discussion, my partner and I came up with a tentative scope of the new project:
- Automatic deployment, management, and deletion of virtual environments based on user specification
- Web interface for users to manage virtual environments
- Real-time status/performance monitoring (for both clusters and virtual environments)
- Displaying real-time metrics via web interface
My partner had a general idea about related technologies to achieve said features, and I was introduced with names like Kubernetes, Terraform, Ansible. I was first suggested to learn about OpenStack before further discussions.
Learning about OpenStack
My introduction to OpenStack
The first thing I did was to find out what OpenStack even is. Their website provided an overview:
OpenStack is a set of software components that provide common services for cloud infrastructure.
They also wrote the following:
Cloud Infrastructure for Virtual Machines, Bare Metal, and Containers
Openstack controls large pools of compute, storage, and networking resources, all managed through APIs or a dashboard.
Beyond standard infrastructure-as-a-service functionality, additional components provide orchestration, fault management and service management amongst other services to ensure high availability of user applications.
As I read the high-level overview, I was reminded of LVM concepts; the way the two operate seemed similar, allocating virtual resources out of a pool of aggregated physical resources. They, of course, do differ in scope of resources they manage.
It looked like OpenStack’s features aligned with the project’s scope. I decided to dig deeper.
OpenStack components
I read Canonical’s explanation of the technology, with the following diagram about the platform’s core services:
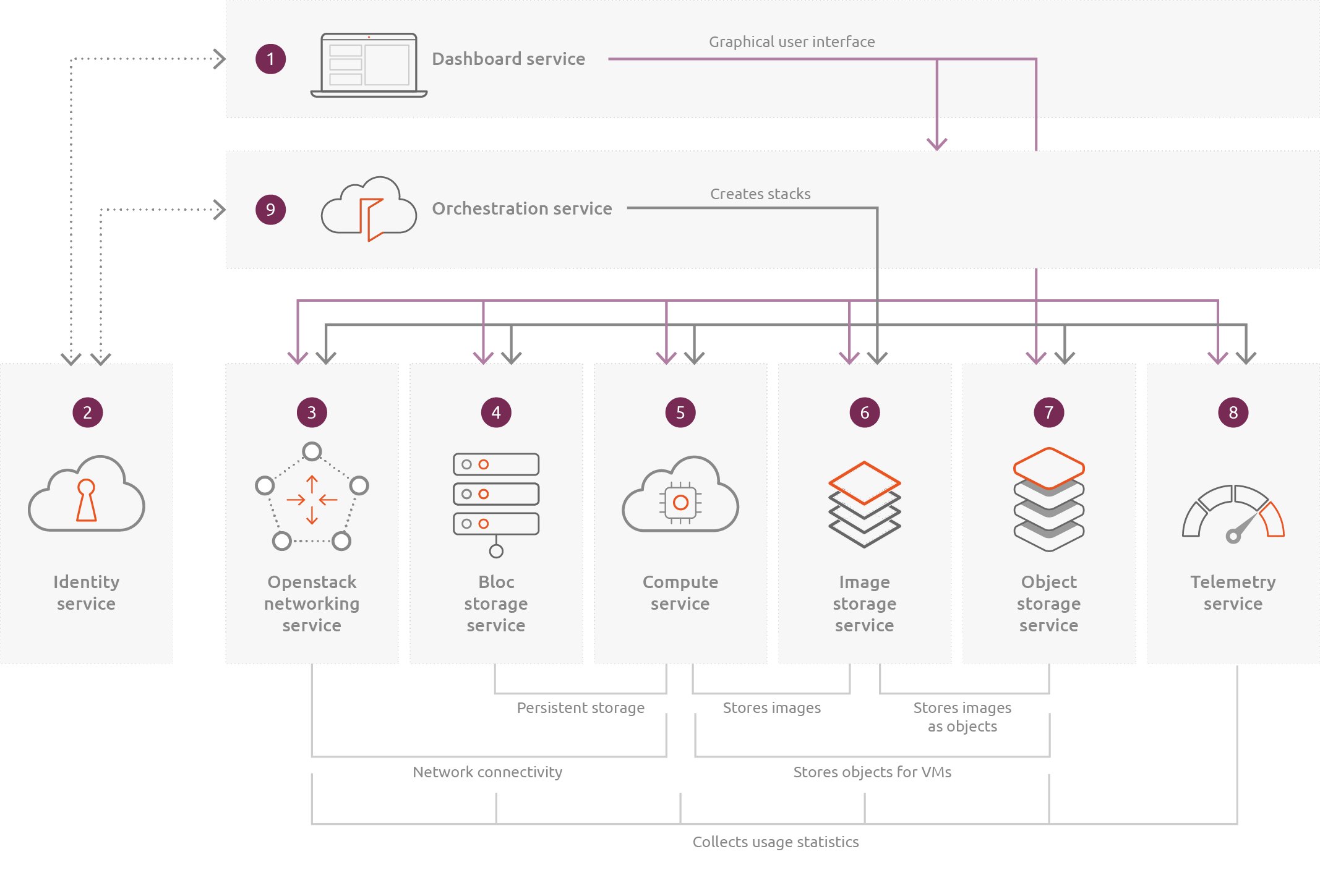
OpenStack consists of components that interact with each other. I took a look at its core services, with names that did not seem very descriptive.
Dashboard (Horizon)

Horizon is the canonical implementation of OpenStack’s dashboard, which is extensible and provides a web based user interface to OpenStack services.
Taking a quick look at its source, I could see that Horizon presents a user interface for interacting with OpenStack services.
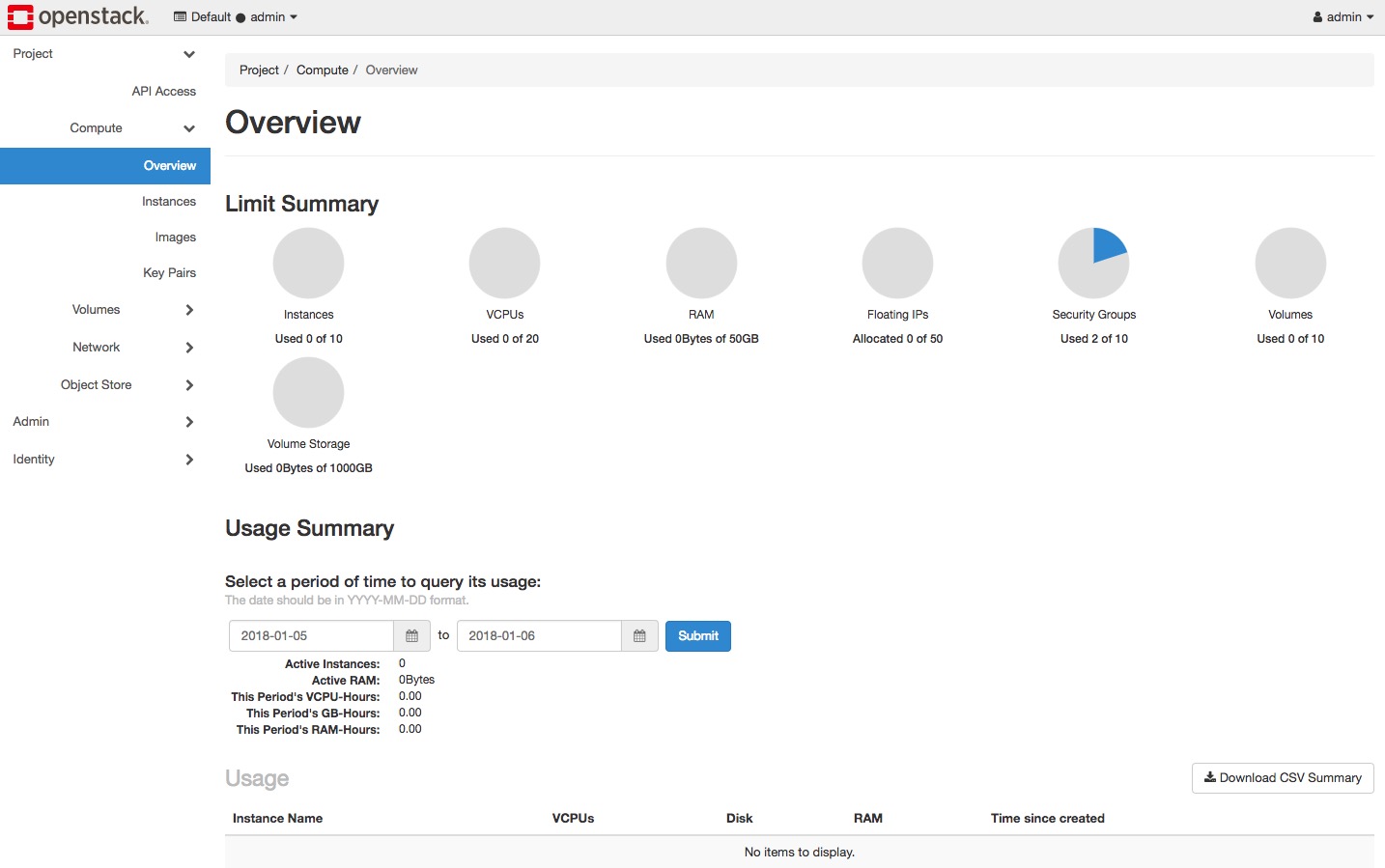
I thought referring to this project may be needed at times to write my own web interface.
Identity service (Keystone)

Keystone is an OpenStack service that provides API client authentication, service discovery, and distributed multi-tenant authorization by implementing OpenStack’s Identity API. It supports LDAP, OAuth, OpenID Connect, SAML and SQL.
Reading a little bit of documentation and source, what I could understand with my little knowledge in web authentication was that it provides means to authentication via HTTP endpoints.
Networking (Neutron)
OpenStack Neutron is an SDN networking project focused on delivering networking-as-a-service (NaaS) in virtual compute environments.
I was worried if I could understand what it exactly does, as I did not consider networking to be my strength. I decided to come back to it another time, after making a brief understanding that it manages network in virtual environments.
Block storage (Cinder)

Cinder is a Block Storage service for OpenStack. It virtualizes the management of block storage devices and provides end users with a self service API to request and consume those resources without requiring any knowledge of where their storage is actually deployed or on what type of device. This is done through the use of either a reference implementation (LVM) or plugin drivers for other storage.
I briefly read the documentation, and it was interesting to see LVM being used as a reference implementation for managing storage for virtual environments.
Compute service (Nova)

To implement services and associated libraries to provide massively scalable, on demand, self service access to compute resources, including bare metal, virtual machines, and containers.
I noticed that Nova deals with virtual machines, providing access to compute resources on demand.
Image service (Glance)

Glance image services include discovering, registering, and retrieving virtual machine images. Glance has a RESTful API that allows querying of VM image metadata as well as retrieval of the actual image. VM images made available through Glance can be stored in a variety of locations from simple filesystems to object-storage systems like the OpenStack Swift project.
Glance felt somewhat similar to Docker Hub or Quay Container Registry, in that they offer images users can apply.
Object store (Swift)

Swift is a highly available, distributed, eventually consistent object/blob store. Organizations can use Swift to store lots of data efficiently, safely, and cheaply. It’s built for scale and optimized for durability, availability, and concurrency across the entire data set. Swift is ideal for storing unstructured data that can grow without bound.
I was initially unsure if I should compare it to another object storage service like S3. However, I did notice that Swift offers API that is partially compatible with the Amazon-owned product.
Metering & Data Collection Service (Ceilometer)

Ceilometer’s goal is to efficiently collect, normalise and transform data produced by OpenStack services. The data it collects is intended to be used to create different views and help solve various telemetry use cases. Aodh and Gnocchi are two examples of services extending Ceilometer data.
With the project’s scope including monitoring virtual environments’ performance, it was a delight to see basic performance stats already in a list of metrics Ceilometer is able to gather.
Orchestration (Heat)

Heat orchestrates the infrastructure resources for a cloud application based on templates in the form of text files that can be treated like code. Heat provides both an OpenStack-native ReST API and a CloudFormation-compatible Query API. Heat also provides an autoscaling service that integrates with the OpenStack Telemetry services, so you can include a scaling group as a resource in a template.
I have heard about using something like templates (like what Heat uses) to programmatically deploy services. It looked like something I will benefit from as I integrate it with the project.
What now?
After taking a brief and high-level look at OpenStack, I could somehow see what it aims to do. I felt deploying one could be feasible, but at the same time, I still had a lot to learn.
Looking at OpenStack’s source, it was obvious that a lot of Python was used. I personally do not mind what programming languages to use (maybe except Java), so it was not a big concern to me.
I intend to try running OpenStack next time, but I will have to go back to learning if I get stuck.